 Rohit Arora
Rohit Arora
system design basics
Introduction
Typically, designing a system involves many variables and a good design is the most important piece of puzzle when it comes to implementation and deployment of an application.
The following steps are very helpful in order to design a reliable, efficient and scalable system for any application:
- Step 1: Requirement Clarifications
- Step 2: Capacity Considerations
- Step 3: System Interface Definitions (Defining APIs)
- Step 4: Data Model Definitions
- Step 5: High Level Design
- Step 6: Detailed Design
- Step 7: Handling Bottlenecks and Failures
Step 1: Requirement Clarifications
It is always a good idea to go over the requirements and ask open-ended questions to understand the expectations out of the system and clear any ambiguities in the system design. We should also clarify what parts of the design problem need detailed analysis as time is limited in a session.
As an example, if we are designing a twitter like service, we should ask the following questions:
- Will the users be able to post tweets and follow other people?
- Should we design to create and display user’s timeline?
- Will the tweets contain photos and videos?
- Are we focusing on the backend or should be also design a front-end?
- Will the users be able to search tweets?
- Do we need to display trending topics?
- Will there be any push notifications for new (or important) tweets?
These questions help define the overall expectations from the system and a high level design.
Step 2: Capacity Considerations
It is always a good idea to estimate the scale of the system as it will help to make decisions on scaling, partitioning, load balancing and caching.
For example:
- What scale is expected out of the system? (# of new tweets, # of views, # of timeline generations per second etc.)
- How much storage do we need? We have different storage requirements if we also have photos vides on the tweets.
- What kind of memory or cashing do we need to consider?
- What network bandwidth usage should we be expecting? This will define how we balance server load and traffic using load balancers?
Step 3: System Interface Definitions
We need to define how the system interacts with the outside world, We should define APIs to establish the exact contract expected out of the system. This also helps to validate requirements.
For the above example:
- post_tweet(user_id, tweet_data, user_location, timestamp, …)
- generate_timeline(user_id, current_time, current_location, timestamp)
- mark_tweet_fav(user_id, tweet_id, timestamp)
Step 4: Data Model Definitions
Defining the data models will clarify how the the data flows between all the components of the system. These models will help define how to partition the data and manage storage. We should be able to identify how the different system components interact with each other. How is data managed in terms of storage, transportation, encryption etc.
In our twitter like service example, these are the data models:
User: user_id, user_name, user_email, user_phone_no, user_dob, user_last_login, user_last_login_location etc. Tweet: tweet_id, tweet_content, tweet_location, tweet_timestamp, tweet_number_of_likes etc. Followers: user_id, [ user_ids ] Favorite_Tweets: user_id, [ tweet_ids ], time_stamp
What kind of database we should use? SQL (MySQL) or NoSQL (Cassandra)? What kind of block storage should we use to store photos and videos?
Step 5: High Level Design
It’s ideal to draw a basic diagram with high level blocks to identify how the system will look like. Are we covering all aspects of the design end to end?
For the twitter example:
- We need multiple application servers to serve all read/write requests with load balancers for distributing traffic evenly. Is our system read intensive? - we need more load balances to optimize read rather than write.
- On the backend, we need a database that can support huge number of reads and can store a large number records. We need fast and efficient storage to store photos and videos.
| | /-------> Databases
/------> | App Server 1 | /
____ /\ / | |/
__/ \___ / \ / | App Server 2 |
/ Clients \-------->/ LB \/---------> | |
\___ ____/ \ /\ | App Server 3 |
\__/ \ / \ | .. |\
\/ \-------> | .. | \
| App Server n | \-------> File Storage
| ______________ | Step 6: Detailed Design
Discuss in detail the area relevant to the discussion based on the feedback. We should be able to present different approaches to solve a problem and discuss pros and cons of each approach. There is NO single answer so we have to discuss tradeoffs between different options while keeping system constraints in mind.
Examples:
- How will we store massive amount of data, how to partition our data to distribute to multiple database? If we keep all user’s data on the same database, what issue would it cause?
- How will we handle hot users who tweet a lot or follow lots of people? How about celebrities?
- Since user’s timeline will contain most recent tweets, how should we store the data, so its optimized for scanning the latest tweets by a user?
- How much cache do we need and at what layer?
- Where all do we need to introduce load balancing?
Step 7: Handling Bottlenecks and Failures
We should also identify as many bottlenecks and failure scenarios as possible and suggest different approaches to mitigate them.
- What are we doing to eradicate single points of failure (SPOF)?
- Do we have enough replicas of the database to still serve our users in case of data loss?
- Do we have enough instances of our services running to still server our users even if few application servers go down?
- How are we monitoring the system performance> Do we get alerts whenever critical components fail or performance degrades?
System Design Basics
When designing a large system, we need to consider 3 things:
- What are the different architectural pieces that we can use?
- How do these pieces work with each other?
- How can be utilize these pieces? What are the tradeoffs?
Investing in scaling before it’s needed is not a good business idea, but we need to have a design ready so we can same some and and resources at the time.
Below, we discuss the key characteristics of a well designed system.
Key Characteristics of a Distributed System
A distributed system must have these key characteristics be Scalability, Reliability, Efficiency, Availability and Manageability (-> ScREAM)
Scalability
It is the capability of a system, process or a network to grow and manager increased demand. Any distributed system that can continuously evolve to serve the growing needs is considered to be scalable.
We may have to scale due to many reasons like, increased data volume or increased transactions per second etc. A perfectly scalable system should be able to scale without any performance hit.
But generally, system performance declines as the size increases because of management and environment costs. For example, response times may increase because machines tend to be far apart from each other and it takes time to compute the response. Some tasks may not be able to be distributed because of their inherent atomic nature. At some point such tasks will limit the speed up obtained by distribution. A scalable system attempts to load balance evenly on all participating nodes before such a situation arises.
Horizontal vs. Vertical Scaling
Horizontal Scaling means that you add scale by adding more servers into your pool of resources whereas vertical scaling means that you scale by adding more power (CPU / RAM / Storage) to your existing servers.
Horizontal scaling is easier as you can dynamically add more servers to the pool. Vertical scaling is limited by the max capacity of the single server and scaling beyond that will require shutting down that server and upgrading, meaning downtime and that too has a limit.
For databases, Cassandra and Mongo DB are good examples of horizontal scaling as they both provide an easy way to add more machines to the pool. My SQL however is good example of vertical scaling as you can switch to a bigger machine. This process involves downtime.
Reliability
By definition, Reliability is the probability that a system will fail in a given period of time. More simple, a system is considered reliable, if it keeps delivering service even when one or more of its hardware or software components have failed. Reliability is the main characteristic of any distributed system because the failing component can always be replaced by a healthy one, ensuring the completion of the requested task.
For example, in case of Amazon, if a user can initiated a transaction, it should never be cancelled due to a system failure, similarly, if a customer has a few items in cart, it is expected that it never get lost. A reliable distributed system achieves this with redundancy of both software and hardware components and data. If a server hosting the shopping cart of a customer fails, another server is expected to take over without any impact to the customer’s shopping cart.
Redundancy has a cost and a reliable system has to pay and to achieve such resiliency by eliminating every single point of failure.
Availability
By definition, Availability is the time a systems stays operational to perform its required function in a specific perid of time. It is measured as a percentage of time that a system, service or a machine keeps functioning under normal conditions. For example, an aircraft that can be flown for many hours in a month without any downtime or maintenance can be said to be highly available. Availability accounts for maintainability, repair times, spares availability and other logistical considerations. An aircraft down for maintenance is not available at the time.
Reliability is availability over time considering the full range of possible real-world conditions that can occur. For example an aircraft that can make a safe journey in any kind of weather is reliable that the one that can operate in thunderous conditions.
Reliability vs. Availability
If a system is reliable, it’s also available; However if a system is available, it does not make it reliable by default. High Reliability automatically means the system is also highly available. But the opposite is not true.
It is possible to achieve high availability even with an unreliable product by minimizing the downtime and making sure repairs and spare parts are always available at all times.
For example, an aircraft that is highly available as it is never down for maintenance, but NOT reliable to make a safe journey through thunderous whether or high turbulence. If that aircraft makes a journey through high turbulence, we can’t say for sure it is safe, because there is a chance it may result in a catastrophe.
Efficiency
Two standard measures of efficiency in a distributed system are:
- Latency (or response time) that denotes the delay introduced by the system between input and its corresponding output.
- Bandwidth (or throughput) that denotes the number of items output by the system per unit time.
Indirectly, Latency corresponds to the size of messages per transaction representing the total volume of transactions and Bandwidth of the system corresponds to the number of transactions processed by the system regardless of the size of each of each transaction.
The complexity of the operations supported by the distributed system can be characterized as a function of one of these measures.
Generally speaking, analyzing the distributed system performance in terms of number of transactions in overly simplistic. It ignores the impact of network topology, network load and its variation, heterogeneity of the software and hardware components involved in processing, routing etc. On the other hand, it’s very difficult to define a precise model that accounts for all these performance factors. Which is why we have to live with rough, but robust estimates of the system behavior.
Manageability (or Serviceability)
Another important consideration while designing a distributed system is how easy it is to operate and maintain. It also refers to the speed and simplicity with which a system can be replaced or maintained. If the time to repair a failed system increases, its availability decreases. It also includes the ease of diagnosing and understanding where and when the problems occur, ease of making updates where necessary and generally how simple it is to operate the system. Does the system break often during regular operation? How about during updates?
Detecting faults before they happen can avoid or at least decrease down time. For example sending alerts when the system is nearing its capacity, or spawning additional service threads in such a case. Or directly calling support systems when a component fails without human intervention.
All these factors listed above are the key features of a robust distributed system.
Now we will discuss the basic building blocks in a distributed system and how we can use these concepts discussed above to make it more robust.
Building Blocks of a System
A distributed system consists of basic things like compute, databases, storage, cache, memory, networking etc. The following is a list of building blocks which we will discuss in more detail going further.
- Load Balancing
- Caching
- Data Partitioning
- Indexes
- Proxies
- Queues
- Redundancy and Replication
- SQL vs. NoSQL
- CAP Theorem
- Consistent Hashing
- Long Polling vs. Websockets vs. Server-Sent Events
1. Load Balancing
Load Balancers (LBs) are a critical system component as they help distribute the load among multiple instances of services running on a cluster of servers to improve responsiveness and availability of applications, databases or websites etc. A good load balancing system also keeps track of the utilization of each cluster member while distributing load, so as to efficiently utilize all the the available resources. If a server stops responding or has an elevated error rate, the LB will stop sending any further traffic to that server.
Typically a LB sits between clients and servers and accepts all traffic incoming from the clients and distributes it across multiple backend servers using various algorithms. By doing this the LB reduces load on each service instance, preventing any one application server from becoming a single point of failure, therefor improving overall application availability and responsiveness.
| |
C /------> | App Server 1 |
\ ____ /\ / | |
\___/ \___ / \ / | App Server 2 |
C --/ Clients \-------->/ LB \/---------> | |
\___ ____/ \ /\ | App Server 3 |
/ \___/ \ / \ | .. |
/ \/ \-------> | .. |
C | App Server n |
| ______________ |To further improve redundancy, LBs can be introduced at multiple layers so as to balance load on each layer of the system.
Three logical points in a web application would be for example:
- Between client and web server
- Between web server and internal platfrom layer (application server or cache servers etc.)
- Between internal platform layer and database servers.
|--------| --------- ---------
C /->| | /->| | /->| |
\ /\ / | | /\ / | | /\ / | |
\__ /\__ / \ / | Web | / \ / | App | / \ / | Database|
C -/Clients\-->/ LB \/---->| Servers|-->/ LB \/ | Servers |-->/ LB \/---->| Servers |
\___ __/ \ /\ | | \ /\ | | \ /\ | |
/ \/ \ / \ | | \ / \ | | \ / \ | |
/ \/ \-->| | \/ \-->| | \/ \-->| |
C | | | _______ | | _______ |
| ______ | Benefits of Load Balancing
- Faster user experience, uninterrupted service. Users wont have to wait for a single struggling server to finish previous tasks, Instead their requests are passed on to the next available resource.
- Service providers experience lesser downtime and higher throughput. Even a full server failure won’t impact the end user experience and the load balancers will simply route to another healthy server.
- Load Balancing also makes it easy for system administrators to handle incoming requests and schedule maintenance windows for some servers without impacting the service.
- Smart Load Balancers also provide opportunities for predictive analytics that determine traffic bottlweightedenecks before they happen. As a result organizations get actionable insights, which are key to automation and help drive business decisions.
- There are fewer stressed system components and lesser overall failures as there are many servers doing little bit work, as compare to a single server, doing all the work.
Load Balancing Algorithms
A Load Balancer chooses a healthy backend server on the basis of a pre-configured algorithm which make sure the servers are not given unfair amount of work.
However, the Load Balancer first needs to identify if a server in the pool is health or not. For that, all servers in the pool are polled intermittently (health checks) to make sure the servers are listening. If a server fails a health check, it is automatically removed from the pool and traffic is not forwarded to that server until it to health checks correctly.
The following load balancing methods are most popular and are used for different purposes.
Least Connection Method - This method forwards traffic to the server which the fewest active connections. This approach is quite useful when there are a large number of persistent client connections which are unevenly distributed between the servers.
Least Response Time Method - This algorithm directs traffic to a server with the fewest active connections and the lowest average response time.
Least Bandwidth Method - This method selects the server that is serving the least amount of traffic bandwidth-wise (measured in Mbps).
Round Robin Method - This is the most trivial method and cycles through all the healthy servers one by one. At the end of the list, it starts from the beginning of the list once again. It forwards every new request to the next server in line, regardless of how busy that server is at the moment. This is why this method is most useful when all servers in the pool are of the exact same specifications and there are not a lot of persistent connections.
Weighted Round Robin Method - This algorithm is designed to to better handle servers with different processing power. Each server is assigned a weight which is an integer number based on it its processing power. Server with higher weights receive higher number of connections before a lower weighted server is selected. Also higher weighted servers get a higher number of connections.
IP Hash - This method calculates the hash of source and destination IP address and connects a client to the same server that was previously used. This method enhances the performance for session based traffic because it gives the client an opportunity to resume the same connection it was using before as compared to dropping and restarting another connection on another server.
Redundant Load Balancers
Overall, Load Balancers are a good way to distribute traffic among a pool of application servers, however LBs can fail too. A simple way to get around this issue is to have an active-passive load balancer cluster. Each LB monitors the health of other members in a cluster and passive load balancer takes over if the active fails.
| |
| active | ________________
| /\ | | |
C cluster -> | /LB\ | ------> | App Server 1 |
\ ____ | \ / | | |
\___/ \___ | \/ | | App Server 2 |
C --/ Clients \-----> | | ------> | |
\___ ____/ | /\ | | App Server 3 |
/ \___/ | /LB\ | | .. |
/ | \ / | ------> | .. |
C | \/ | | App Server n |
| passive | | ______________ |2. Caching
Adding more servers to a load balancer pool definitely helps to scale an application, but enabling caching leads to even better utilization of available resources, making it a vital component in building a robust distributed system.
Caching can help take advantage of the locality of reference principle: recently used data is likely to be requested again.
Caches are used in almost every layer of computing: hardware, operating systems, web-browsers, web-applications etc. A cache is like a short-term memory: it has a limited amount of space, but typically faster than the original data source and contains the most recently accessed items. Caches can exist at all levels in architecture, but are often found closer to the client as compared to server, so that data is processed on the spot without bothering the backend.
Application Server Cache
Placing a cache directly on the request layer node enables local storage of response data. Each time request is made to the service, the node will quickly return local cached data if it exists. If it is not in the cache, the requesting node will query that data from the disk. The cache on the request layer can be located in memory (RAM) or on the node’s local disk (faster than obtaining the data from a network storage).
If the application request layer is extended over multiple server nodes, each server can still have its own cache. But if a load balancer is involved, it will lead to a lot of cache misses because the request will go to different server each time. Global Caches and Distributed Caches are typically used to avoid such scenarios.
Also IP hashing based load balancers avoid this problem as the IP address of the client does not change as often.
Content Distribution Network
CDNs come into play for large websites that serve a lot of static media. Generally, a client will first query a CDN node for a piece of static media; the CDN node will serve that request if it is locally available. It it isn’t cached at the CDN layer, the CDN will query the back-end server for the file, cache it locally and serve it to the requesting user.
If the system isn’t big enough for a CDN today, we can serve it off a separate subdomain using a lightweight HTTP server like NGINX, so it is easy for a DNS cutover from self-hosted media servers to a CDN at a later stage.
Cache Invalidation
Caching is a wonderful solution to improve responsiveness and reducing latency when serving a request. However, it has to be kept coherent with the source of truth (database) at all times. If the data is modified in the database, it has to be updated in the cache (known as cache invalidation) as well, else it will cause inconsistent behavior.
There are 3 main schemes used for cache invalidation:
- Write-through Cache
- Write-around Cache
- Write-back Cache
Write-through Cache is a scheme where data is written into the cache as well as the corresponding database the the same time. The cached data allows for fast access to data and also has complete consistency with the database as it is written to database at ehe same time is it is update in the cache. This scheme also ensures that nothing gets lost in the event of a crash or a power failure or other service disruptions.
The only disadvantage with this scheme is that it introduces latency for write operations as writes have to happen twice for the same data - once to the cache and second to the database.
Write-around Cache is a scheme where data is written directly to the database server, bypassing the cache completely. This can help reduce the flood of write operations to the cache, but will create a cache-miss of data that is just written to the database moments ago. This creates a new request to read and refill the cache with the response data from slower permanent storage and therefore introduces latency.
Write-back Cache is the most interesting scheme out of the three. Under this scheme, data is only written to the cache at write time and completion is immediately relayed to the client. The writing to permanent storage happens periodically after a specific interval or under certain conditions. This can provide a boost to the latency and results in high-throughput for write-intensive applications, however there is a risk of losing cached data in case of sudden crashes, because cache contains the only copy of the data before it is written to permanent storage.
Cache Eviction Policies
Below are the most common cache eviction policies used today.
- FIFO - First In First Out - This policy just removes the first block accesses first without any regard to how many times it has been accessed before.
- LIFO - Last In First Out - This policy evicts the most recently accessed block first, without any regard to how many times it has been accessed before.
- LRU - Least Recently Used - Discards least recently accessed blocks first.
- MRU - Most Recently Used - Discards most recently access blocks first. (opposite to LRU)
- LFU - Least Frequently Used - This policy keeps a count of how often a block is used. Those blocks that are used least often are evicted first.
- RR - Random Replacement - This policy randomly evicts a block to make space when necessary.
Although, all approaches above have specific purposes, LRU or LFU cache eviction policies are most commonly used.
3. Data Partitioning
Data Partitioning is a technique that is used to break up a big database into many smaller parts. This means spitting up a table / DB across multiple machines to improve performance and better load balancing of an application. Data Partitioning is logical after a certain point as it get cheaper and more feasible to scale horizontally as compared to vertically.
Partitioning Methods
Out of many different schemes to break up an application database into smaller DBs, these three are the most popular ones, which are used for various large scale applications.
Horizontal Partitioning
In this scheme, we put different rows in different tables. This is also called range based partitioning are we store different ranges of data in different databases. Data Sharding is another name for it.
As an example, if we are storing geographical locations in a database, we can decide thats locations with zipcode < 10000 are stored in one table and locations with zipcode > 10000 are stored in another table. This is a classic example of range based partitioning. There is however, a problem with this approach. If the value whose range is used for partitioning is not chosen carefully, then the partitioning scheme will lead to an unbalanced databases. In the above example, splitting locations based on zipcode assumes that places will be evenly distributed across different zipcodes, but that may not be true since heavily populated cities in New York City may have a large number of zipcodes as compared to a suburb city.
Vertical Partitioning
In this scheme, we divide our data to store tables related to a specific feature in its own server. For example, for an instagram like service, we store user’s profile information on one server, user’s photos on another server and their friend lists on another.
Vertical Partitioning is straightforward to implement and has a low impact on the application. The main problem with this approach is that if we see more growth, it may become inevitable to further partition a feature specific DB across multiple servers.
Directory-based Partitioning
A relatively better approach to work around these issues is to create a look-up service which knows about the DB partitioning scheme and abstracts the data access away from the database. To find a piece of data, the application will query the directory service that holds the mapping between each key it it’s database entry. This loosely coupled approach allows us to add more servers to the DB pool where needed and not worry about needing to partition again or needing to change our partitioning scheme when the data set grows, without impacting the application in any way.
Partitioning Criteria
Key or Hash-based Partitioning
Under this scheme, we apply a hash function to a key attribute of the entity that we want to store, which gives us a partition number. For example, if we have 100 DB servers and we are storing a record with a numeric ID that increments by 1, then hashing function - “100 % ID”, gives us a number between 1 - 100, which is basically our server ID to store that record. This approach would lead to a uniform distribution of data. But we face a fundamental problem with this approach if the user base grows and we need to add more servers, which will change the hashing function and hence will lead to redistribution of entire database meaning downtime.
A workaround for this problem is using Consistent Hashing.
List Partitioning
This approach requires a list of values assigned as keys to each partition. So when we want to insert a record, we lookup a partition that contains our key and then store it in that partition. As an example, we can store user information for users living in Finland, Norway or Sweden on a single partition marked for Scandinavian countries.
Round-Robin Partitioning
This is a simple strategy that ensures uniform data distribution. With ’n’ partitions, the ‘i’ tuple is assigned to the partition number (i % n)
Composite Partitioning
Under this scheme, we combine any of the above approaches to form a new scheme. As an example, we can first apply a list partition scheme and then apply a hash-based scheme for partitioning the data across multiple servers.
Consistent hashing is a composite of hash and list partitioning where the hash reduces the key space to a size that can be listed in a partition.
Common Problems
Partitioning across different servers introduces certain extra constraints on the operations that can be performed on the data. Below are some of those constraints and additional complexities:
Joins and Denormalization
Performing Joins on database running on a single server is easy, but once a database is partitioned and spread across multiple machines, it is not feasible to perform joins that space database partitions. Such joins will not be performance efficient since that data has to be compiled from multiple servers. We can of course, denormalize the database to perform the required joins from a single table, but that brings up data inconsistency issue which is a common issue with denormalization.
Referential Integrity
Just like performing a cross-partition query is not feasible, similarly, trying to enforce data integrity constraints such as foreign keys in a partitioned database is very difficult. Most of RDBMS do not support foreign key constraints across databases spanning multiple servers. This means applications that need referential integrity have to enforce it in the application layer, running regular SQL jobs to clean up the loose ends (dangling references).
Rebalancing
We may have to change out partitioning scheme due to many reasons along the way, for example:
- Data distribution is not uniform - e.g. there are too many places for a particular zipcode to fit in a single partition.
- There is a lot of load on a partition - e.g. there are too many requests to the photos database.
In cases like these, we have to create more DB partitions or rebalance existing partitions, leading to all existing data being reshuffled across multiple servers in various locations. This is extremely difficult to do without any downtime, unless you have 2 copies of the entire database running in synchronization at all times. Directory based partitioning does make rebalancing easier, but it increases complexity and creates a single point of failure. The lookup service has to be made redundant to get around this limitation.
4. Indexes
Sooner or later, there comes a time when the database performance is no longer satisfactory, meaning the database has become so big that running queries, adding records, fetching records becomes really slow with respect to its growing size. Thats when database indexing comes into play.
The goal of creating an index on a particular table in a database is to make it faster to search through the table and find the records we want. We can create indexes using one or multiple database columns leading to faster random lookups and efficient access of ordered records.
A real life example is a index table in the front of a book. You can of course find the relevant information by reading each and every page of the book, but an index in the front gives you a specific page number, so that you can jump in to that exact set of pages and find the relevant information much faster than reading all the pages in the book.
In technical terms, an index is a data structure that stores the pointers to the location where a particular record is stored. So when we create an index on a column of a table, we store that column and a pointer to the whole row in the index.
Example:
Index Record
1. [Adam, A] A. [ Adam, Engineer, 28, New York ]
2. [Nicole, C] B. [ Jill, HR, 37, New Jersey ]
3. [Cindy, D] C. [ Nicole, Recruiter, 28, California ]
4. [Jill, B] D. [ Cindy, Engineer, 26, Texas ]Why Indexing?
Like a traditional relational dataset, we can apply the same concept to larger databases. The trick with indexing is to carefully consider how the users are going to look for the data and use that information to pick a column as an index. In large datasets with small sized records (consider 1 KB records in a database spanning multiple TBs), indexing is a necessity for optimal data access as we can’t iterate over all the records to find the relevant record in reasonable time. Further, such a large database is likely to span over multiple physical devices, meaning we need to find a way to locate the relevant data across physical devices. Indexing is the best way to do it.
Disadvantage of Indexing
An index can speed up data retrieval dramatically, but may get very large itself and it may slow down insertion and updation. Secondly, by adding or updating records in a table with an active index, we have to write the data in 2 places and we need to also update the index in addition to writing data in the database, which decreases the write performance.
The performance hit impacts all operations on a database with an active index. For this reason, it should be noted that adding unnecessary indexes to a database is not a good idea and any unused indexes should be removed from the database.
So if we are not doing a lot of search queries, but simply writing the data to a database, indexing will add unnecessary complexity to the database and in fact, slow the system down. Decreasing the performance of the more common operation - writing is probably not worth as compared to the performance boost we get from indexing the database.
5. Proxies
A proxy server is an intermediate server between the clients and the back-end server. Clients connect to the proxy server to request a resource like a web-page or a file or a connection etc. It is basically a piece of software or hardware that acts an intermediary for clients requesting resources from a server.
Proxies are used to filter requests, log requests or sometimes modify requests (by adding/removing headers, encrypting decrypting, or compressing a resource). A proxy server can also serve as a cache for a lot of requests requesting the sam resource.
Types of Proxy Server
Proxy servers can reside on a client’s local server, or anywhere between the client and the server. Open Proxy and Reverse Proxy are two popular types of proxy servers.
Open Proxy
This can be accessed by any user on the Internet and used as a forwarding service. It has 2 types:
-
Anonymous Proxy - This type of service basically hides the IP address of the requester and passes the request as its own to the destination. Although it can be easily discovered, it is popular as it anonymizes the users.
-
Transparent Proxy - This type of service does not hide the user IP address but is used to cache the websites which the users are making requests to. For example, if a lot of users are accessing a popular blog, each time a request is made, the response is cached. In the event that the publisher takes the blog down, users still have access to the last cached instance of the website.
Reverse Proxy
This type of service actually fetches the resources from the server on the behalf of its clients. The resources are returned to the clients as if they originated from the proxy server itself.
6. Redundancy and Replication
Redundancy is the duplication of critical components or functions of a system with the intention of increasing the reliability of the system, usually in the form of a backup or a fail-safe, or to improve system performance. For example, if a file is only stored on a single server, losing that server means losing the file. So we can create duplicate (or redundant) copies of the file to minimize the risk of losing that file.
It plays an important role in mitigating the single point of failure in a system. For instance, we have two instances of our service running in production and the active instance fails, the standby instance takes over without loss of service.
Replication however means, sharing data between redundant resources to ensure consistency and improve fault-tolerance and reliability. For example, a database service running in master-slave configuration where master gets the record updates first and then copies the update over to multiple slave databases and slave databases acknowledge each update. In the event of a failure of the primary database, one of the slaves can be made the primary without any loss of data or service downtime.
7. SQL vs. NoSQL
There are mainly two types of databases: SQL and NoSQL (or relational and non-relational databases). Both differ in the way they are built, the kind of information they store and the storage method they use.
Relational databases are structured and have predefined schemas like the address and phone number of a person. Non-relational databases are unstructured, distributed and have a dynamic schema which can store everything about a person like their address, phone numbers and also their facebook likes, videos they shared and their online shopping preferences.
Relational data is stored in columns and rows and has well defined structure. Each row contains all the information about an entity with columns containing specific data points. MySQL, Oracle, MS SQL Server, SQLite, Postgres, MariaDB are some examples.
There are multiple types of NoSQL databases depending on what data they store and what advantage each has on different types of data. Following are some popular NoSQL database types:
Key-Value Stores - These databases store data in an array of key-value pairs. The ‘key’ is an attribute name which is linked to a value. Common Example are Redis, Voldemort, DynamoDB, Riak, BerkeleyDB etc
Document Databases - These databases store data in complex data structures called documents and these documents are grouped together as collections. Each document can have a completely different structures like key-value pairs or key-array pairs and can even contain nested documents. Examples are Mongo DB and Couch DB.
Wide-Column Databases - These databases store data in terms of column families, which can be thought of as containers for rows. We don’t need to know all the columns upfront and each row can have different number of columns and can contain any data type. Columnar databases are best suited to analyze large data-sets. Cassandra and HBase are two popular examples.
Graph Databases - These databases are used to store data which is best represented as a network or a graph (like social connections). Data is saved in graph data structure with nodes, their properties and connections between the nodes. Examples are Neo4J, Giraph, InfiniteGraph.
Key differences
Storage
- SQL stores data in tables where each row represents a record and each column represents an attribute of that record.
- NoSQL databases have different data models. Key Value, document, graph and columnar are a few types.
Schema
- In SQL, each record conforms to a fixed schema, meaning columns will be decided before the data is entered and each column must be populated when adding a record. Schema can be altered, but it will involve changing the whole database and taking the service down.
- In NoSQL, schemas are dynamic. Columns can be added on the fly and each column does not need a value for the data to be inserted.
Querying
- SQL databases use Structured Query Language (SQL) to define and manipulate data.
- In NoSQL, queries are focused on a collection of documents, sometimes referred to as UnQL (Unstructured Query Language). Different databases have different syntax.
Scalability
- Most SQL databases are vertically scalable, meaning we can increase the database capacity by adding higher capacity hardware (more RAM, more powerful processor etc.). Scaling relational databases horizontally (using multiple servers) is possible but very complex and time consuming.
- NoSQL databases are designed to be horizontally scalable, meaning we just add more servers to handle more traffic. Any low cost hardware is able to host a portion of NoSQL database, making it very cost effective to scale up as compared to vertical scaling. Most NoSQL databases can be configured to automatically distribute data across all available servers.
Reliability or ACID Compliance (Atomicity, Consistency, Isolation, Durability)
- Relational databases are generally ACID compliant, so when it comes to data reliability and safe guarantee of performing transactions, SQL databases are a good bet.
- Most NoSQL databases sacrifice ACID compliance for performance and scalability.
Which to use where?
Most solutions rely on both relational and non-relational databases for different needs. NoSQL databases are gaining popularity, but in some use cases only a SQL database can fit the measure.
Why SQL?
These are a few reasons to use SQL databases in the solution:
- SQL should be chosen if we need to ensure ACID compliance. ACID compliance reduces the chance for anomalies and protects the integrity of the database, by defining the exact schema for transactions to interact with the database. No SQL databases sacrifice ACID compliance for performance and scalability, but for commercial or financial applications, ACID compliant SQL databases are the optimal choice.
- If the data to be stored is structured and unchanging, SQL databases are the better choice. If a solution is not in the phase of massive growth that we definitely need scalability, or if the data is consistent, then there is no reason to use NoSQL which is designed for a variety of data types and high volume.
Why NoSQL?
When all other components of the solution are fast and seamless, SQL databases may become a bottleneck that slows the system down. In such cases NoSQL databases can help. Big Data is one of the major contributors to the success of NoSQL databases because it handles data differently as compared to a SQL database. MongoDB, CouchDB, Cassandra and HBase are a few examples.
- NoSQL databases allow the applications to store large volume of data that have little to no structure. There are no limits imposed by the NoSQL database with regards to the type of data that we can store together and we can add new types as required. In document-type databases we don’t have to define the type of data in advance.
- NoSQL databases allow us to make the most of cloud computing and storage. Cloud storage can help drive the costs down, but the data has to be designed to be spread across multiple servers to support scalability. Any commodity hardware can be used to host the database on-site or it can be hosted in the cloud. Most NoSQL databases are designed to spread across multiple data centers for horizontal scaling.
- NoSQL can be very useful for rapid development of the application as the database does not have to be prepped before time. If the application in in development phase and the database schema changes often, NoSQL databases can help speed up the iterations with minimal downtime. A relational (SQL) database will slow things down as it needs to be re-populated after each schema change.
8. CAP Theorem
CAP Theorem states that a distributed system can only provide 2 out 3 following guarantees at a time: Consistency, Availability, Partition Tolerance
When designing a system, this is the first tradeoff that we have to consider.
Consistency: All nodes see the same data at a given time - all nodes have to be updated before allowing any reads.
Availability: The system needs to respond for every request despite any failures - data has to be replicated across multiple servers to handle failures.
Partition Tolerance: The system needs to work despite partial failure. A partition tolerant system will continue to work without an issue unless the whole network goes down. Data is sufficiently replicated across the whole system (multiple nodes and networks) to sustain despite intermittent outages.
The picture below shows an example:
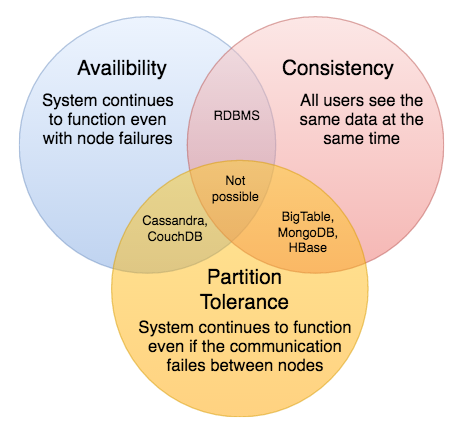
As per the theorem, it is impossible to build a system that is continually available, sequentially consistent and tolerant to partition failures at the same time.
As an example, for a system to be sequentially consistent, all nodes should see the same set of updates in the same order. But if the network suffers a partition (meaning some nodes go down, resulting in two partitions of the network), updates in one partition might not make it to the other partition before a client sends a read request to an out-of-date partition. We can choose to not serve the client from the of-of-date node, but that will make the system not 100% available.
9. Consistent Hashing
sfdsdf
10. Long Polling vs. Websockets vs Server-sent Events
sdfg